Authors Junwon Park, Ranjay Krishna, Pranav Khadpe, Li Fei-Fei, Michael Bernstein Abstract To support the massive data requirements of modern supervised machine learning (ML) algorithms, crowdsourcing systems match volunteer contributors
CategoryResearch
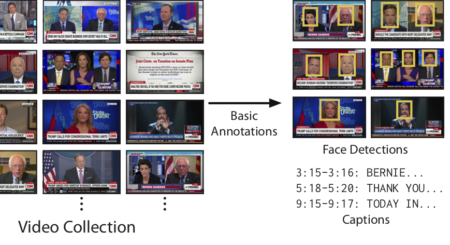
Video Event Specification using Programmatic Composition
Authors Daniel Y. Fu, Will Crichton, James Hong, Xinwei Yao, Haotian Zhang, Anh Truong, Avanika Narayan, Maneesh Agrawala, Christopher Ré, Kayvon Fatahalian Abstract Many real-world video analysis applications require the

Text-based Editing of Talking-head Video
Authors O. Fried, A. Tewari, M. Zollhöfer, A. Finkelstein, E. Shechtman, D. B Goldman, K. Genova, Z. Jin, C. Theobalt and M. Agrawala Image: We propose a novel text-based editing
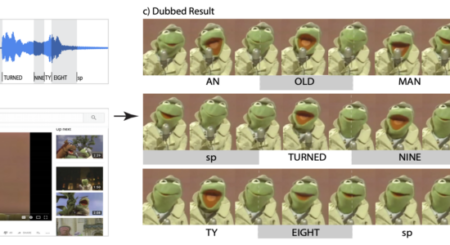
Puppet Dubbing
Given an audio file and a puppet video, we produce a dubbed result in which the puppet is saying the new audio phrase with proper mouth articulation. Specifically, each syllable
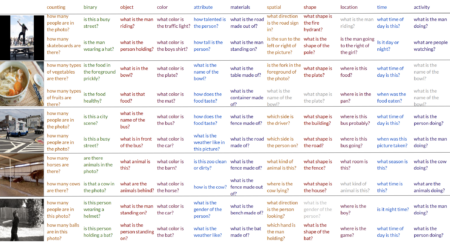
Information Maximizing Visual Question Generation
Example questions generated for a set of images and answer categories. Incorrect questions are shown in grey and occur when no relevant question van be generated for a given image
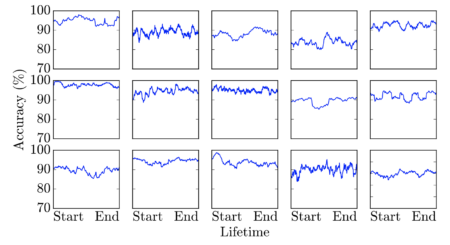
A Glimpse Far into the Future: Understanding Long-term Crowd Worker Accuracy
A selection of individual workers’ accuracy over time during the question answering task. Each worker remains relatively constant throughout his or her entire lifetime. Authors Kenji Hata, Ranjay Krishna, Li
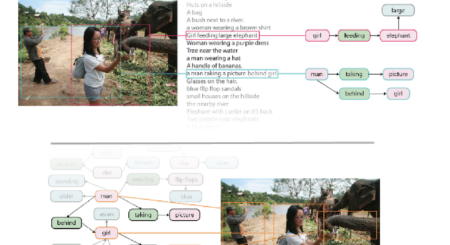
Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations
An overview of the data needed to move from perceptual awareness to cognitive understanding of images. We present a dataset of images densely annotated with numerous region descriptions, objects, attributes,

Visual Relationship Detection with Language Priors
Even though all the images contain the same objects (a person and a bicycle), it is the relationship between the objects that determine the holistic interpretation of the image. Authors

Generating Semantically Precise Scene Graphs from Textual Descriptions for Improved Image Retrieval
Actual results using a popular image search engine (top row) and ideal results (bottom row) for the query a boy wearing a t-shirt with a plane on it. Authors Sebastian