
Graphical (or pictorial) presentations of data have become an almost essential part of journalistic practice. Data visualization helps us see patterns in data and is an important tool for finding
CategoryResearch

Upcoming Event – Using FOIA with Muckrock (9/29 from 12-1:30PM)
A Talk and demo of MuckRock, a website empowering citizens and journalists to write, file and track public records requests online, and its new FOIA Logs tool September 29 from
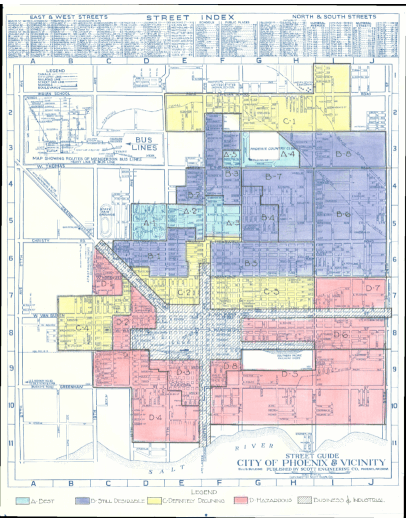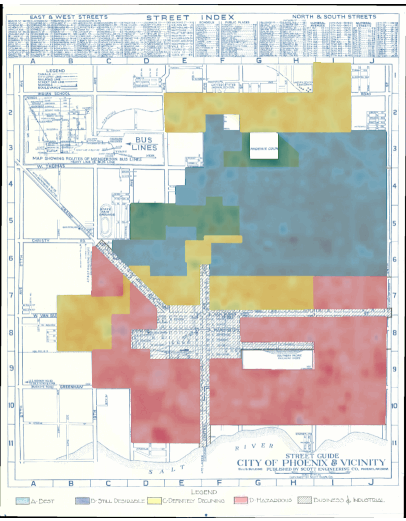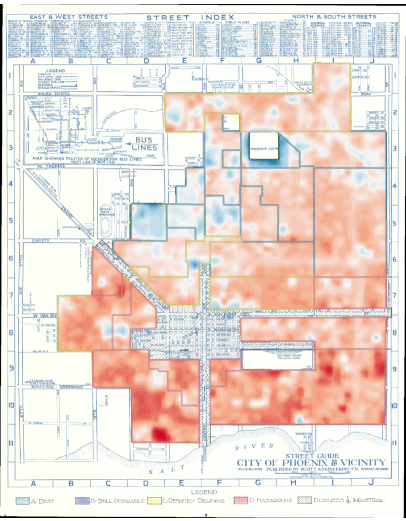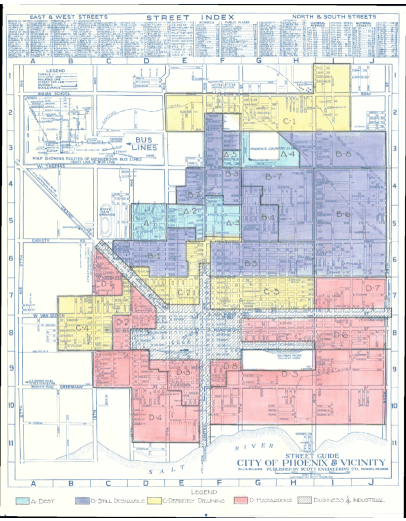
Announcing ‘Grades of Heat’: A Tool to Explore the Thermal Footprints of HOLC Grading
In 1933, amidst the Great Depression, Franklin D. Roosevelt’s New Deal gave rise to the Home Owners’ Loan Corporation (HOLC), an effort aimed at preventing widespread foreclosures. However, this effort

Notes from NYCML and CHANEL’s Synthetic Media Challenge
Over the Spring semester, I participated in the NYC Media Lab’s Synthetic Media challenge, in collaboration with CHANEL. This challenge brought together teams of faculty and students from a variety
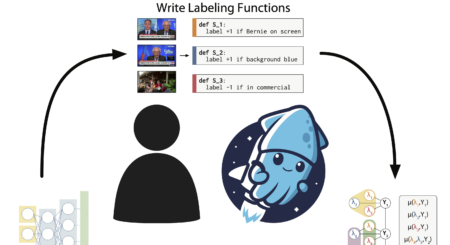
Fast and Three-rious: Speeding Up Weak Supervision with Triplet Methods
Authors Daniel Y. Fu, Mayee F. Chen, Frederic Sala, Sarah M. Hooper, Kayvon Fatahalian, Christopher Ré Abstract Weak supervision is a popular method for building machine learning models without relying
Multi-Resolution Weak Supervision for Sequential Data
Authors Frederic Sala, Paroma Varma, Jason Fries, Daniel Y. Fu, Shiori Sagawa, Saelig Khattar, Ashwini Ramamoorthy, Ke Xiao, Kayvon Fatahalian, James R. Priest, Christopher Ré Abstract Since manually labeling training
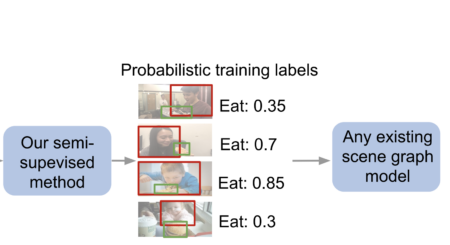
Scene Graph Prediction with Limited Labels
Authors Vincent Chen, Paroma Varma, Ranjay Krishna, Michael Bernstein, Christopher Re, Li Fei-Fei Image: Our semi-supervised method automatically generates probabilistic relationship labels to train any scene graph model. Abstract Visual
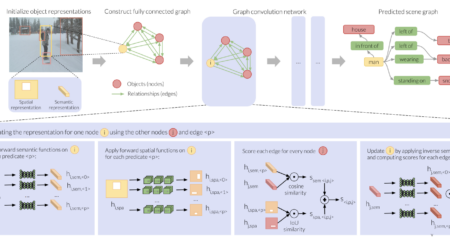
Visual Relationships as Functions: Enabling Few-Shot Scene Graph Prediction
Authors Apoorva Dornadula, Austin Narcomey, Ranjay Krishna, Michael Bernstein, Li Fei-Fei Image: We introduce a scene graph approach that formulates predicates as learned functions, which result in an embedding space

View-Dependent Video Textures for 360° Video
Authors Sean J. Liu, Maneesh Agrawala, Stephen DiVerdi, Aaron Hertzmann Image: In 360◦ video, viewers can look anywhere at any time. In the opening scene of Invasion!, a rabbit emerges