Authors
Apoorva Dornadula, Austin Narcomey, Ranjay Krishna, Michael Bernstein, Li Fei-Fei
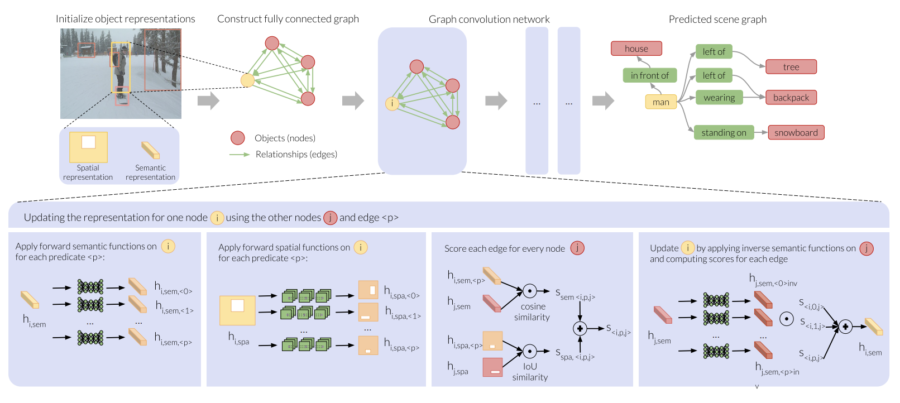
Image: We introduce a scene graph approach that formulates predicates as learned functions, which result in an embedding space for objects that is effective for few-shot. Our formulation treats predicates as learned semantic and spatial functions, which are trained within a graph convolution network. First, we extract bounding box proposals from an input image and represent objects as semantic features and spatial attentions. Next, we construct a fully connected graph where object representations form the nodes and the predicate functions act as edges. Here we show how one node, the person’s representation is updated within one graph convolution step.
Abstract
Scene graph prediction — classifying the set of objects and predicates in a visual scene — requires substantial training data. The long-tailed distribution of relationships can be an obstacle for such approaches, however, as they can only be trained on the small set of predicates that carry sufficient labels. We introduce the first scene graph prediction model that supports few-shot learning of predicates, enabling scene graph approaches to generalize to a set of new predicates. First, we introduce a new model of predicates as functions that operate on object features or image locations. Next, we define a scene graph model where these functions are trained as message passing protocols within a new graph convolution framework. We train the framework with a frequently occurring set of predicates and show that our approach outperforms those that use the same amount of supervision by 1.78 at recall@50 and performs on par with other scene graph models. Next, we extract object representations generated by the trained predicate functions to train few-shot predicate classifiers on rare predicates with as few as 1 labeled example. When compared to strong baselines like transfer learning from existing state-of-the-art representations, we show improved 5-shot performance by 4.16$ recall@1. Finally, we show that our predicate functions generate interpretable visualizations, enabling the first interpretable scene graph model.
The research was published in IEEE International Conference on Computer Vision – Scene Graph Representation and Learning on 10/31/2019. The research is supported by the Brown Institute Magic Grant for the project Learning to Engage in Conversations with AI Systems.
Access the paper: https://arxiv.org/pdf/1906.04876.pdf
To contact the authors, please send a message to ranjaykrishna@cs.stanford.edu