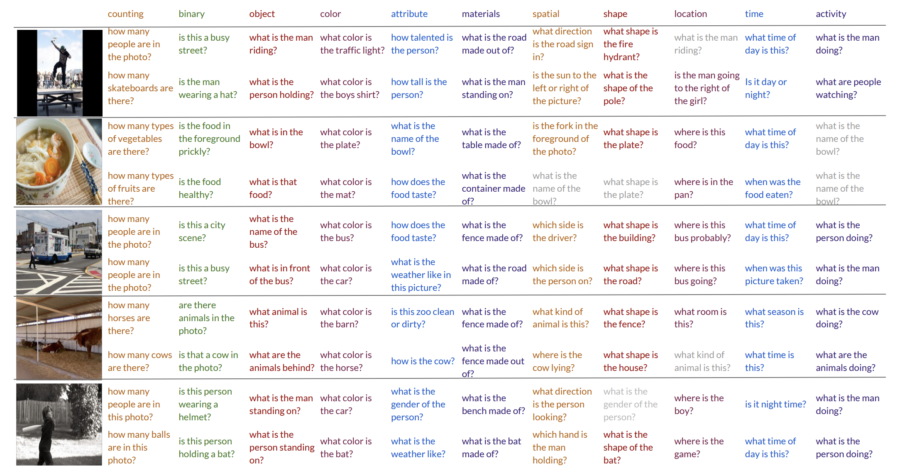
Example questions generated for a set of images and answer categories. Incorrect questions are shown in grey and occur when no relevant question van be generated for a given image and answer category
Authors
Ranjay Krishna, Michael Bernstein, Li Fei-Fei
Abstract
Though image-to-sequence generation models have become overwhelmingly popular in human-computer communications, they suffer from strongly favoring safe generic questions (“What is in this picture?”). Generating uninformative but relevant questions is not sufficient or useful. We argue that a good question is one that has a tightly focused purpose — one that is aimed at expecting a specific type of response. We build a model that maximizes mutual information between the image, the expected answer and the generated question. To overcome the non-differentiability of discrete natural language tokens, we introduce a variational continuous latent space onto which the expected answers project. We regularize this latent space with a second latent space that ensures clustering of similar answers. Even when we don’t know the expected answer, this second latent space can generate goal-driven questions specifically aimed at extracting objects (“what is the person throwing”), attributes, (“What kind of shirt is the person wearing?”), color (“what color is the frisbee?”), material (“What material is the frisbee?”), etc. We quantitatively show that our model is able to retain information about an expected answer category, resulting in more diverse, goal-driven questions. We launch our model on a set of real world images and extract previously unseen visual concepts.
The research was published in IEEE Conference on Computer Vision and Pattern Recognition on 6/18/2019. The research is supported by the Brown Institute Magic Grant for the project Learning to Engage in Conversations with AI Systems.
Access the paper: https://arxiv.org/pdf/1903.11207.pdf
To contact the authors, please send a message to ranjaykrishna@cs.stanford.edu