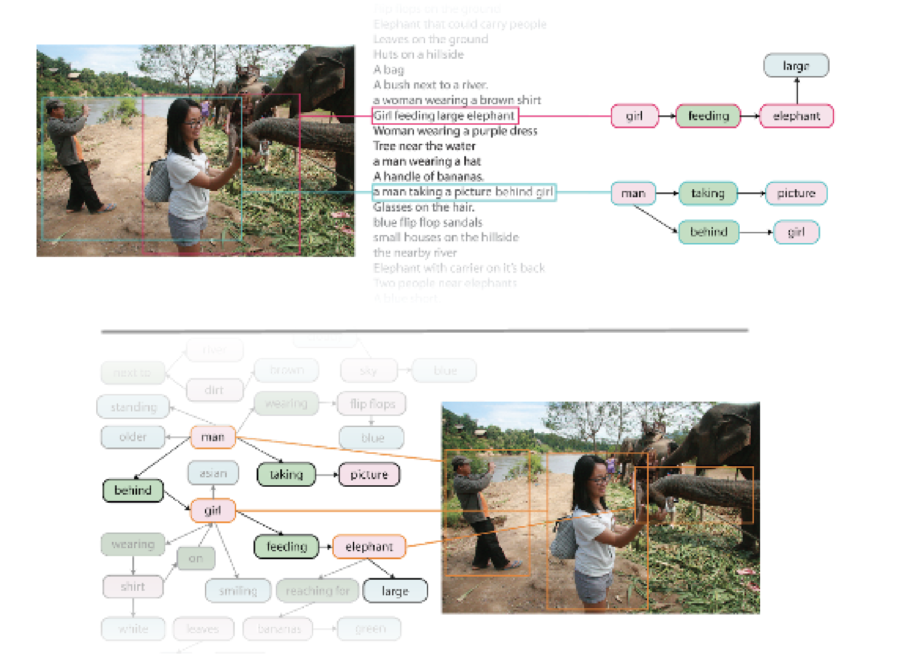
An overview of the data needed to move from perceptual awareness to cognitive understanding of images. We present a dataset of images densely annotated with numerous region descriptions, objects, attributes, and relationships. Region descriptions (e.g. “girl feeding large elephant” and “a man taking a picture behind girl”) are shown (top). The objects (e.g. elephant), attributes (e.g. large) and relationships (e.g. feeding) are shown (bottom). Our dataset also contains image related question answer pairs (not shown). et al
Authors
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li Jia-Li, David Ayman Shamma, Michael Bernstein, Li Fei-Fei
Abstract
Despite progress in perceptual tasks such as image classification, computers still perform poorly on cognitive tasks such as image description and question answering. Cognition is core to tasks that involve not just recognizing, but reasoning about our visual world. However, models used to tackle the rich content in images for cognitive tasks are still being trained using the same datasets designed for perceptual tasks. To achieve success at cognitive tasks, models need to understand the interactions and relationships between objects in an image. When asked “What vehicle is the person riding?”, computers will need to identify the objects in an image as well as the relationships riding(man, carriage) and pulling(horse, carriage) in order to answer correctly that “the person is riding a horse-drawn carriage.” In this paper, we present the Visual Genome dataset to enable the modeling of such relationships. We collect dense annotations of objects, attributes, and relationships within each image to learn these models. Specifically, our dataset contains over 100K images where each image has an average of 21 objects, 18 attributes, and 18 pairwise relationships between objects. We canonicalize the objects, attributes, relationships, and noun phrases in region descriptions and questions answer pairs to WordNet synsets. Together, these annotations represent the densest and largest dataset of image descriptions, objects, attributes, relationships, and question answers.
The research was published in IEEE International Journal on Computer Vision on 1/10/2017. The research is supported by the Brown Institute Magic Grant for the project Visual Genome.
Access the paper: https://arxiv.org/pdf/1602.07332.pdf
To contact the authors, please send a message to ranjaykrishna@cs.stanford.edu